
Contenidos
Herramientas de big data
Herramientas de procesamiento de big data
Las 10 mejores herramientas de análisis de Big DataEl aumento del uso de la tecnología en los últimos años también ha provocado un incremento de las cantidades de datos que se generan por minuto. Todo lo que hacemos en línea genera algún tipo de datos.
Una serie de informes, Data Never Sleeps (Los datos nunca duermen), de DOMO, recoge la cantidad de datos que se generan cada minuto. En la octava edición del informe, se muestra que un solo minuto de Internet tiene más de 400.000 horas de transmisión de vídeo en Netflix, 500 horas de vídeo transmitido por los usuarios en Youtube, y casi 42 millones de mensajes compartidos a través de WhatsApp.
El número de usuarios de Internet ha alcanzado los 4.500 millones, casi el 63% (según nuestros cálculos) del total de la población mundial. Se espera que la cifra aumente en los próximos años, ya que asistimos a una expansión de las tecnologías.
El análisis de big data es un proceso que permite a los científicos de datos hacer algo con la pila de big data generada. Este análisis de big data se realiza utilizando algunas herramientas que consideramos como herramientas de análisis de big data.
R-Programming es un lenguaje de programación de dominio específico diseñado específicamente para el análisis estadístico, la computación científica y la visualización de datos utilizando R Programming. Ross Ihaka y Robert Gentleman lo desarrollaron en 1993.
Herramientas de big data para el aprendizaje automático
La biblioteca de software Apache Hadoop es un marco de trabajo de big data. Permite el procesamiento distribuido de grandes conjuntos de datos en clusters de ordenadores. Es una de las mejores herramientas de big data diseñada para escalar desde servidores individuales hasta miles de máquinas.
Atlas.ti es un software de investigación todo en uno. Esta herramienta de análisis de big data le ofrece un acceso todo en uno a toda la gama de plataformas. Puede utilizarlo para el análisis de datos cualitativos y la investigación de métodos mixtos en la investigación académica, de mercado y de la experiencia del usuario.
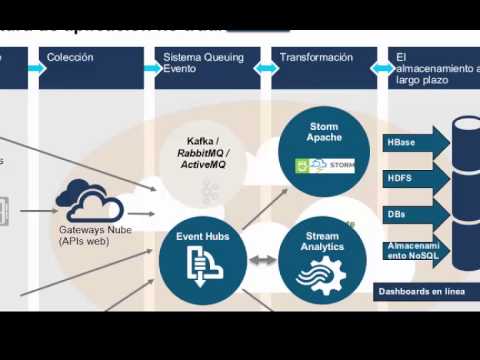
Storm es un sistema gratuito de cálculo de big data de código abierto. Es una de las mejores herramientas de big data que ofrece un sistema de procesamiento distribuido en tiempo real y tolerante a fallos. Con capacidades de computación en tiempo real.
Pentaho proporciona herramientas de big data para extraer, preparar y mezclar datos. Ofrece visualizaciones y análisis que cambian la forma de dirigir cualquier negocio. Esta herramienta de Big data permite convertir los grandes datos en grandes conocimientos.
Open Refine es una potente herramienta de big data. Es un software de análisis de big data que ayuda a trabajar con datos desordenados, limpiándolos y transformándolos de un formato a otro. También permite ampliarlo con servicios web y datos externos.
Cerdo apache
El uso actual del término big data tiende a referirse al uso de la analítica predictiva, la analítica del comportamiento del usuario o algunos otros métodos avanzados de análisis de datos que extraen valor de los big data, y rara vez a un tamaño concreto del conjunto de datos. “Hay pocas dudas de que las cantidades de datos disponibles ahora son realmente grandes, pero esa no es la característica más relevante de este nuevo ecosistema de datos”[4].
El tamaño y el número de conjuntos de datos disponibles han crecido rápidamente a medida que los datos son recogidos por dispositivos como los móviles, los baratos y numerosos dispositivos de detección de información del Internet de las cosas, los aéreos (teledetección), los registros de software, las cámaras, los micrófonos, los lectores de identificación por radiofrecuencia (RFID) y las redes de sensores inalámbricos. [8][9] La capacidad tecnológica per cápita del mundo para almacenar información se ha duplicado aproximadamente cada 40 meses desde la década de 1980;[10] en 2012 [actualización], cada día se generaban 2,5 exabytes (2,5×260 bytes) de datos[11] Según la predicción de un informe de IDC, se preveía que el volumen mundial de datos crecería exponencialmente de 4,4 zettabytes a 44 zettabytes entre 2013 y 2020. Para 2025, IDC predice que habrá 163 zettabytes de datos[12]. Una cuestión para las grandes empresas es determinar quién debe ser el propietario de las iniciativas de big data que afectan a toda la organización[13].
Apache spark
El análisis de big data es el uso de técnicas analíticas avanzadas contra conjuntos de big data muy grandes y diversos que incluyen datos estructurados, semiestructurados y no estructurados, de diferentes fuentes y en diferentes tamaños, desde terabytes hasta zettabytes.
¿Qué son exactamente los big data? Puede definirse como conjuntos de datos cuyo tamaño o tipo supera la capacidad de las bases de datos relacionales tradicionales para capturar, gestionar y procesar los datos con baja latencia. Las características de los big data incluyen un alto volumen, una alta velocidad y una gran variedad. Las fuentes de datos se están volviendo más complejas que las de los datos tradicionales porque están siendo impulsadas por la inteligencia artificial (IA), los dispositivos móviles, los medios sociales y el Internet de las cosas (IoT). Por ejemplo, los diferentes tipos de datos proceden de sensores, dispositivos, vídeo/audio, redes, archivos de registro, aplicaciones transaccionales, web y medios sociales, muchos de ellos generados en tiempo real y a muy gran escala.
Con la analítica de big data, puede impulsar una toma de decisiones mejor y más rápida, la modelización y predicción de resultados futuros y la mejora de la inteligencia empresarial. A la hora de crear su solución de big data, considere el software de código abierto como Apache Hadoop, Apache Spark y todo el ecosistema Hadoop como herramientas de procesamiento y almacenamiento de datos rentables y flexibles, diseñadas para manejar el volumen de datos que se genera hoy en día.